深入浅出RAG
RAG介绍
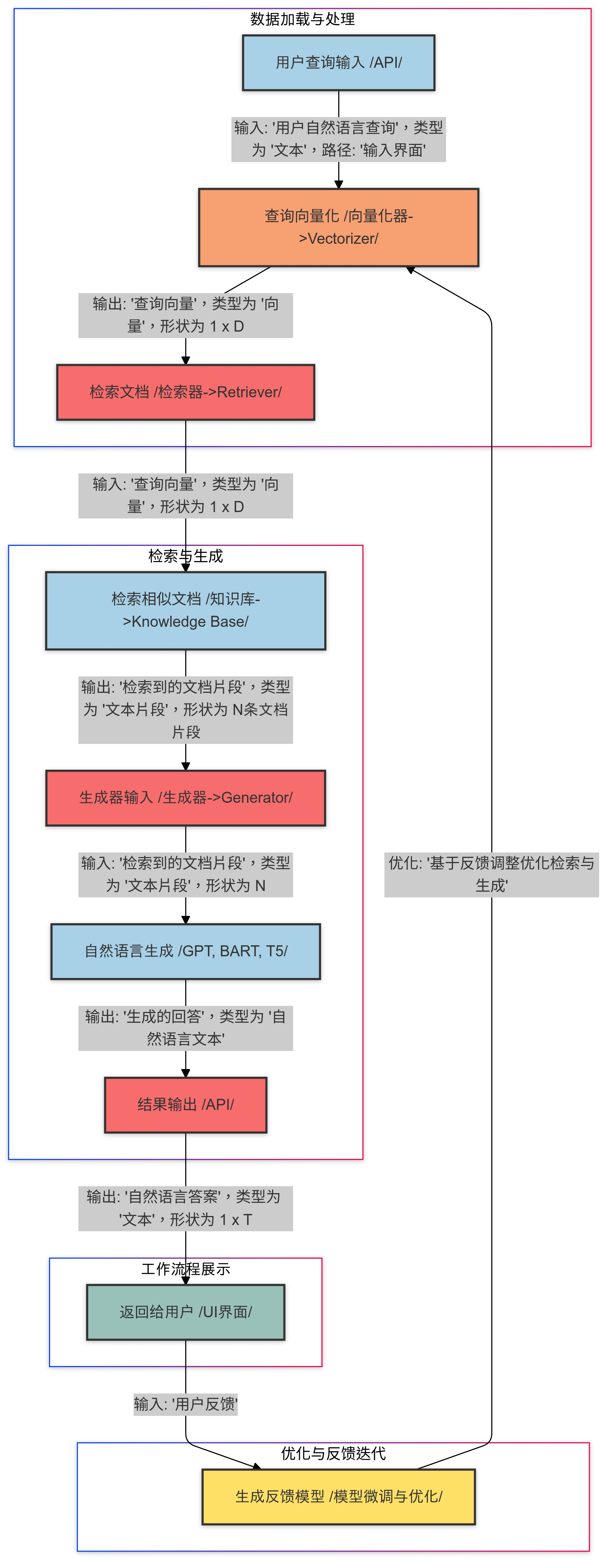
RAG是一种将信息检索与生成模型相结合的混合架构。首先,检索器从外部知识库或文档集中获取与用户查询相关的内容片段;然后,生成器基于这些检索到的内容生成自然语言输出,确保生成的内容既信息丰富,又具备高度的相关性和准确性。 RAG 模型由两个主要模块构成:检索器(Retriever)与生成器(Generator)。这两个模块相互配合,确保生成的文本既包含外部的相关知识,又具备自然流畅的语言表达。 RAG模型的工作原理
检索阶段
在RAG模型中,用户的查询首先被转化为向量表示,然后在知识库中执行向量检索。通常,检索器采用诸如BERT等预训练模型生成查询和文档片段的向量表示,并通过相似度计算(如余弦相似度)匹配最相关的文档片段。RAG的检索器不仅仅依赖简单的关键词匹配,而是采用语义级别的向量表示,从而在面对复杂问题或模糊查询时,能够更加准确地找到相关知识。这一步骤对于最终生成的回答至关重要,因为检索的效率和质量直接决定了生成器可利用的上下文信息 。
生成阶段
生成阶段是RAG模型的核心部分,生成器负责基于检索到的内容生成连贯且自然的文本回答。RAG中的生成器,如BART或GPT等模型,结合用户输入的查询和检索到的文档片段,生成更加精准且丰富的答案。与传统生成模型相比,RAG的生成器不仅能够生成语言流畅的回答,还可以根据外部知识库中的实际信息提供更具事实依据的内容,从而提高了生成的准确性 。
多轮交互与反馈机制
RAG模型在对话系统中能够有效支持多轮交互。每一轮的查询和生成结果会作为下一轮的输入,系统通过分析和学习用户的反馈,逐步优化后续查询的上下文。通过这种循环反馈机制,RAG能够更好地调整其检索和生成策略,使得在多轮对话中生成的答案越来越符合用户的期望。此外,多轮交互还增强了RAG在复杂对话场景中的适应性,使其能够处理跨多轮的知识整合和复杂推理 。
RAG工作流